Information Chaos
We’ve heard this story about information chaos plenty of times by now: The COVID-19 pandemic hit full force and many organizations were faced with the massive digital transformation challenge of shifting to remote work.

In fact, according to AIIM, only about a third of organizations felt that they were “very prepared” for the changes brought on by COVID-19. As a result, unprepared organizations lost time and productivity trying to adjust.
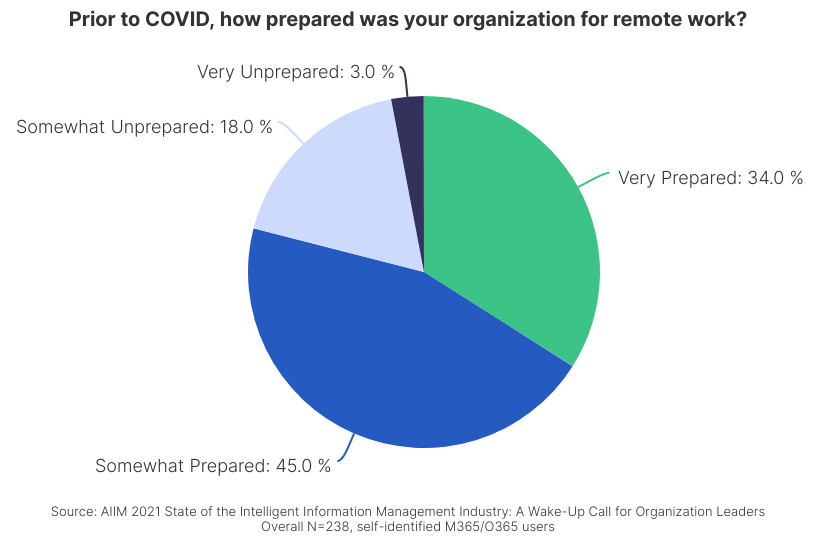
The past year has highlighted weak points in many content management strategies and forced organizations to acknowledge their own vulnerabilities. It was a revelation for many that had no understanding of their level of preparedness until it was too late. Now, these organizations are examining what they missed and making sure they don’t make the same mistakes.
But this raises more questions: What might the next technology emergency look like? What can we improve so we’re better prepared next time?
While there are many factors to consider for disaster preparedness, one of the biggest facing organizations today is information chaos.
It’s time to deal with Information Chaos
Information chaos is not a new problem among organizations. Analysts have known for a while that data volumes are growing steadily each day – and the issue doesn’t stop there. Not only is more data being rapidly created, but there are increasingly different types of data as well, including structured, unstructured data, and even semi-structured data. It is estimated that 80% of today’s data is unstructured.
But like the third of organizations that were digitally prepared for the COVID-19 pandemic, more should prepare for the upcoming tsunami of data.
When it comes to managing information chaos, there are generally two main challenges to address: information volume and information variety.
Challenge 1: Information Volume
Per the AIIM survey, organizations believe that the overall volume of their data will increase by, on average, 4.5x.
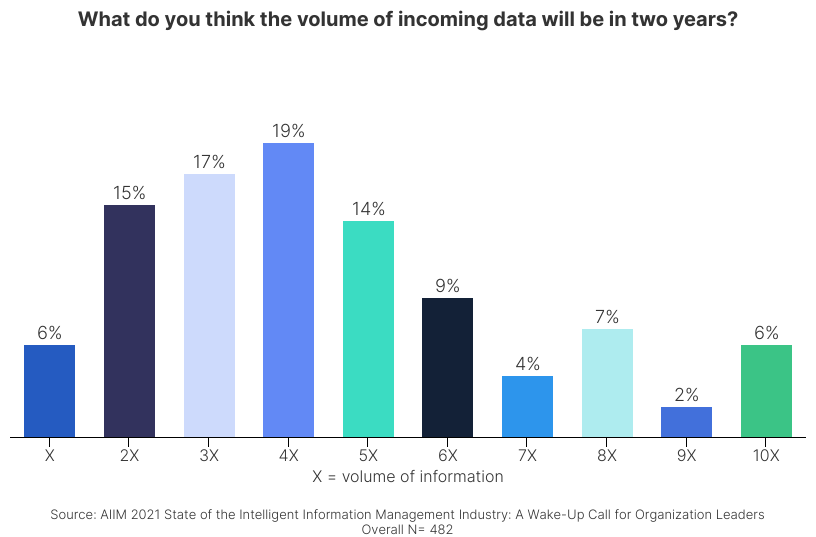
With so much data to govern already, and so much more expected in the coming years, maintaining a grip on enterprise content will pose a huge challenge for many organizations.
Many of us already understand that storage isn’t simply storage. It’s also understanding where the content resides, making sure it’s secured, keeping an eye on any risks that lurk within, how users access and share it, and more. Considering that some companies own many terabytes or even petabytes of content, it would take an extreme amount of manpower and time to govern and control all of that data.
Since workers left the office in March 2020 and every aspect of work was moved online, this problem of unbridled data growth has only been exacerbated.
The Solution: Automated Data Classification
Companies that cannot properly identify the type of information they possess run the continuous risk of security breaches and costly repercussions: large regulatory fines, substantial loss of sensitive data or intellectual property, operational inefficiency, and an overall negative impact on the organization’s overall market value.
The ability to automatically analyze and classify millions of enterprise files at scale (and across multiple systems) can arm an organization with key insights about their content. A truly automated data classification platform discovers content (such as an invoice, agreement, contract, etc.) then analyzes each specific file for any potentially sensitive information or data that may violate privacy laws including GDPR, CCPA, HIPAA, or other regulations. From there, intelligent decisions can be made about how to organize and secure the content no matter where it resides to protect the business and maintain operational efficiency – without the need for a massive manual effort.
Challenge 2: Information Variety
This rising volume of information is made even more complex by the increasing diversity of information types to be managed. Most of this data is of the more complicated unstructured variety.
About 70% of organizations suspect that most of their data is unstructured. This leaves only 30% of organizations guessing their data is mostly structured. As unstructured content grows, companies have adopted numerous storage solutions, making system consolidation difficult and universal oversight nearly impossible.
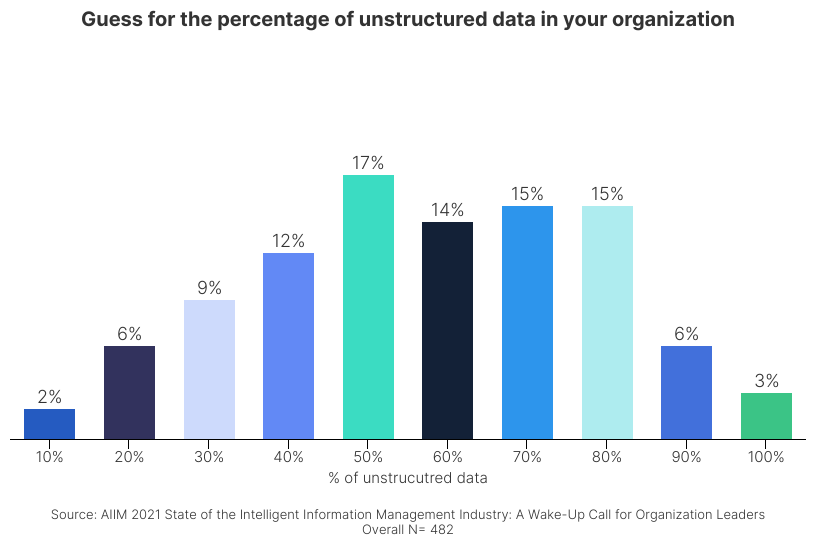
The Solution: Automated Data Orchestration
Once an organization is able to automatically analyze and classify the content spread across the enterprise, the next step is to actually take action on the content. This is where orchestration comes into play: Imagine dumping a bucket of unstructured data into the top of a machine, and what comes out is organized, identified, semi-structured content.
With an automated data governance platform, organizations can easily enforce corporate policy and regulatory compliance without reliance upon any manual effort from users. The platform can simply perform any number of actions based upon the rules set by the organization to ensure the information is properly governed: updating classification labels if necessary, migrating the content to a different repository, or changing access rights are just a few examples.
Avoid Today’s Data Governance Mistakes for Tomorrow
Data can be a double-edged sword. On the one hand, the ability to create and access so much information makes our jobs easier. On the other, if not managed and analyzed correctly these massive volumes of unstructured data can become burdensome. Not to mention that agencies aren’t able to use all of this data to the fullest advantage in its current state.
COVID-19 showed roughly 66% of organizations that neglecting their data landscape left them in crisis mode when disaster struck. Those that employ automation and governance now will have enabled preparedness for the next big shift.
9 Key Recommendations for Organizational Leaders
